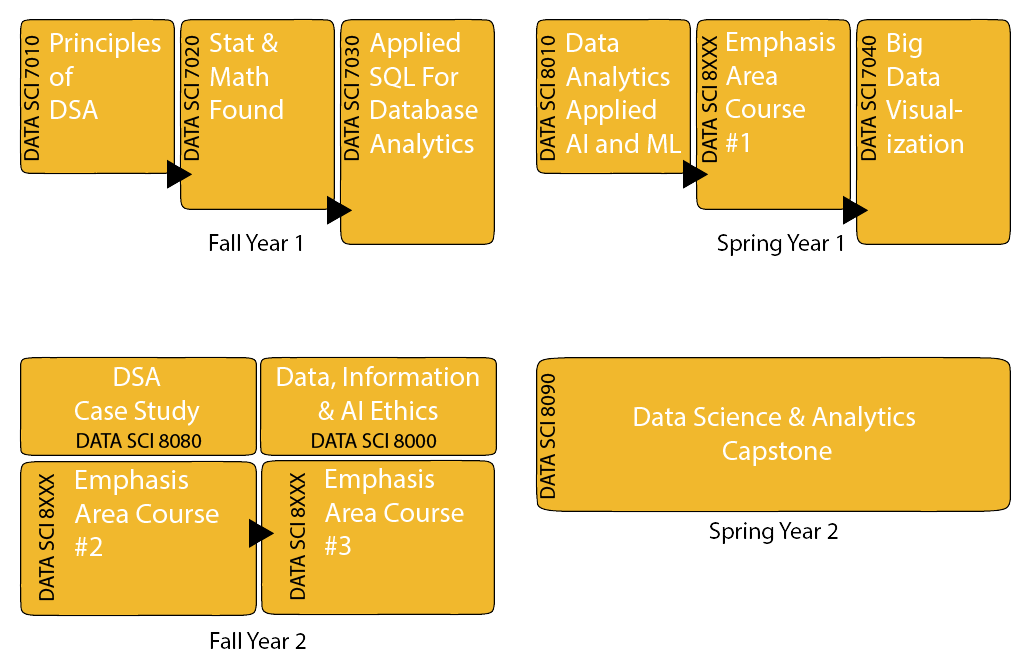
Core Courses
The core course material continually builds upon the Data Science lifecycle theme.
Course work is hands-on, presenting students with increasingly complex data curation as they continue to learn concepts relevant to each particular course.
Additionally, students are continually performing exploratory data analysis and preliminary statistical modeling. Statistical modeling and machine learning are thematic throughout the program.
Finally, the program continually emphasizes the goal of the data science lifecycle, namely achieving business intelligence for the stakeholders (end consumer of the analytics). This storytelling of the data and the analytical processes is also thematic as part of our process to continually develop and refine the students’ soft skills.
A course covering the array of topics and principles involved with data science and analytics. The objective is to provide students a broad overview of the data science life cycle including Students will use generative AI tools, jupyter notebooks and other technology platforms to perform and support hands-on learning and coding through labs, practices, and exercises related to specific analytical topics such as data accessing, cleansing, exploration, analytics, modeling, visualizing, as well as interpreting analytical results. Discussions will be held to ensure that initiate awareness and knowledge of ethical, bias, and other related considerations. Specific coding skills will be expanded through these experiences using Python, R, SQL, and other open source analytic tools.
An intermediate statistics class designed to lay the mathematical principles of predictive analytics and provide a foundation for AI/ML. Topics include discussions of probability, data sampling, data summarization, sampling distributions, statistical inference, statistical pattern analysis, hypothesis testing, regression, nonparametric inference, clustering, and linear algebra over multidimensional data collections. Students will engage in hands-on projects using various publicly available data sets and leveraging current data science tools, techniques, and cyberinfrastructure.
Concentrates on leveraging well-designed relational databases using the entity-relationship model and normalization to extract valuable insights through basic and advanced SQL queries, data manipulation, modeling, ETL, security, and analytics using real datasets. Extended exploration of complex SQL operations such as query optimization, indexing, subqueries, window functions, triggers, and stored procedures supporting advanced analytics, statistics, and reporting needs is integrated through the course. Hands-on practical examples, exercises, and projects combine the essential elements of SQL with practical knowledge in building efficient and well-structured databases, ensuring data integrity, analytical results, and effective reporting. NoSQL, Network, and Geospatial databases are also examined.
This course will cover visualization techniques and methods for a broad range of data types prevalent in engineering disciplines, life sciences, media, and business. Theoretical and practical aspects of information visualization will be taught with a hands-on approach to give students experience in handling data with a set of tools and programming environments. Visualizations toward exploratory data analysis and storytelling will be implemented. Topics will include visual perception and distortions, color theory, pre-attentive processing, data types and models, visual variables, efficient visualizations, design principles, grammar of graphics, spatial visualization, maps, graph theory network visualization, data storytelling including hands-on programming to create plots, charts, heatmaps, spatial and network visualizations using R and Python libraries.
Leverages the foundations in statistics and modeling to teach applied concepts in AI and machine learning (AI/ML). Participants will learn various classes of machine learning and modeling techniques and gain an in-depth understanding of how to select appropriate techniques for various data science tasks and predictive analytics. Topics cover a spectrum from simple Bayesian modeling to more advanced algorithms such as support vector machines, decision trees/ forests, and neural networks. Students learn to incorporate AI/ML workflows into data-intensive analytical processes.
Relates ethical concepts, theories, and frameworks to Big Data, presentation of information, and Artificial Intelligence (AI) in industry, business, academia, and research settings through examination of real-world ethical dilemmas and example situations. Students will learn the social, ethical, legal and policy issues that often underpin big data, data science, and AI phenomena contributing to ethical dilemmas and their resolution. Use of discussions, writing, and interpreting case studies will help guard against the repetition of known ethical mistakes, inadequate ethical awareness, and ethical dilemma resolution preparation.
Advanced Courses
Case studies and capstone allow students to specialize in one or a couple of particular domains.
Interdisciplinary faculty from other MU colleges and schools along with industry leaders help lead domain-specific learning case study and capstone mentoring. With approval, on-Campus students may replace Case Study and Capstone with Thesis Research.
The Data Science and Analytics Case Study is an opportunity for students to work in a small team setting to achieve realistic data carpentry, exploratory analysis, and visualization goals. This is the first opportunity for students to apply what they learned in first year courses to a less structured, real-world problem. Student teams are paired with a faculty mentor who serves in the stakeholder-role for the project. The case study is an opportunity to build your skills as a data scientist while pursuing interests shared by your team and the faculty member. Design of a data science and analytics project guided by the DSA Project Life Cycle Model, applied project management principles, provides the basis for prototyping and communicating a final standalone data story/product using infographics, presentations, R-Shiny, Plotly, or other interactive dashboards and web applications is addressed in this project experience.
The Data Science and Analytics Capstone Project is a research or business-driven project performed over an entire semester to demonstrate realistic design, management, and execution of a full data science project based on the DSA Project Life Cycle Model, ranging from raw data to business insights, knowledge discovery, or automation. This team project will emphasize realistic data carpentry and exploratory analysis using a variety of complex data sources and target and features. The project will include significant domain appropriate statistical or machine learning modeling for knowledge discovery, predictive analytics, or prescriptive analytics. This complete applied data science project builds upon the knowledge and skills developed throughout the DSA program. Student teams are paired with a faculty mentor for the project. This capstone project experience is an opportunity to refine and polish your skills as a data scientist. The presentation of your final capstone standalone data story/product will appropriately demonstrate your work and capabilities as a professional data scientist.
Investigation and research of a data science thesis topic, including exploratory data analysis, statistical modeling, and machine learning. Outcomes will include data-driven insights that advance science, society, or intelligent automation.
Emphasis Area Courses
Emphasis courses represent the final stage in the further refinement of learning with domain-specific data and challenges.
Interdisciplinary faculty from DSA an other MU colleges and schools lead domain-specific learning through emphasis area courses.
BioHealth Analytics
This course will introduce the foundational concepts of genomics and bioinformatics. Genomics is a combination of biological and computational methods that explore the roles of DNA, genes, and proteins on a very large scale. However, understanding how to interpret and understand the results depends (at least) on a basic understanding of biology. The course does not assume a student has a biological background and it will cover the concepts necessary to implement genomics methods.
The integration of multiple types of omics data set such as genomics, epigenomics, transcriptomic, proteomic and metabolomics are very important to understand the pathophysiology of human complex diseases. This course will describe the basic concepts of Multiple types of Omics datasets and databases. This course will also focus on various tools and its application in knowledge discovery from multi-omics data set and its challenges related to preprocessing, analysis and visualization. Hands-on computer experience will be provided through web resources and Jupyter notebook environment.
Credit Hours: 3
This course covers the basic concepts surrounding the analysis of health data. Topics include ethics and regulations of protected health data, healthcare data standards, and statistical analysis and dissemination techniques suitable for health care settings. Project work involves accessing and analyzing real (de-identified) health care data. This course focuses on health data analysis that is done in industry, insurance, hospitals and research. Practical, hands-on course with focus on fundamental data science skillsets such as programming in Python and data carpentry.
This course covers advanced topics in health data analysis. Students will learn about research informatics and clinical trials, and advanced statistical methods used in health data analysis. Additionally, students will be exposed to new forms of health data processing such as free text data, image data, and longitudinal data. Students will explore the use of machine learning and AI in health care settings, and applied clinical informatics in the form of decision support. Project work involves accessing and analyzing real (de-identified) health care data.
Geospatial Analytics
This course provides a deeper dive into the theoretical, conceptual, foundational, and practical issues encountered when working with geospatial data (both vector and raster). A focus on integrating and leveraging geospatial data into a data science database and project as well as the concept of ‘thinking spatially’. Data discovery, access, evaluation of use, retrieval, projection, datum, loading, and other technical and data carpentry concepts are investigated. Important aspects of geospatial database design and storage paradigms (enterprise versus desktop) are explored along with addressing Geospatial Big Data. Core issues in geospatial data storage, management, exploitation, feature engineering, multi-data set entity resolution / correlation, and dealing with special data types such as elevation (3D) and time-series are also examined.
Provides an overview of key issues encountered when working with and analyzing the various forms of spatial data (raster, vector, 3-D, temporal) as well as an overview of major spatial analysis tools, application areas, and analytical approaches. Simple geostatistical measures of centrality, advancing to spatial autocorrelation, geographic weighted regression, and various forms of interpolation. Laboratory, practice, and exercise work will focus on implementation, geostatistical analysis, and derived analytical spatial measures to inform context. Discussions will focus on interpretation issues given constraining factors that commonly arise in practice.
This course provides an overview of key principles of Artificial Intelligence/Machine Learning (AI/ML) as applied to imagery analysis and advanced geospatial analytics. This will include classification of imagery (land cover), change detection, anomalies identification, and forecasting / prediction. The course also delves into and discusses both theoretical and practical issues associated with dynamic spatial systems and techniques such as digital twins, smart cities, as well as touching on spatial simulation methods (i.e., agent-based modeling and cellular automata). Labs, practices, and exercises cover standard geospatial AI processing techniques, including preprocessing and normalization, pixel-level feature extraction, information extraction, classification, data fusion, downscaling, and image understanding. Graded on A-F basis only.
Human-Centered Science Design
Covers the fundamentals of advanced, interactive visualizations by applying theoretical aspects of visualization and communications within an interactive programming environment to create web applications and dashboards to teach interactive design principles to design and implement interactive predictive and exploratory interfaces for data analytics. Conceptual topics include cognition and visual perception, cognitive bias, sensory-level mechanisms in visual perception, human-centered design and evaluation, interaction techniques, evaluation of efficiency, user interface styles. Extensive hands-on programming practices and exercises include learning the Shiny platform for creating interactive web applications to display, manipulate, and explore data with efficient, interactive visualizations for purposes of predictive analytics, and a brief introduction to HTML and Javascript.
Usability is concerned with how well a person can use a designed system to accomplish the goals for which that system is designed. This course provides an overview of methods for usability testing of data science applications through readings, examples and discussions. Students will work in groups to develop and present a usability test plan for a data science application or system.
Data Journalism/Strategic Communication
This course offers an introductory exploration of Natural Language Processing (NLP) techniques in the context of generative AI, with a focus on NLP for Computational Social Science and Large Language Models (LLM). Designed for students with no prior experience in NLP and machine learning principles, this course provides a comprehensive introduction to NLP, applications of basic and advanced NLP techniques, capabilities, and workings of generative AI models. Discussion of NLP methods will be particularly geared towards their application to computational social science research.
This course provides hands-on experience using several digital platforms such as Facebook Insights, Google AdWords, Google Analytics, Adobe Analytics, Clarabridge and Topsy. In this course, you’ll learn digital advertising terminology and jargon, the importance of digital analytics, the role of analysts, qualities of effective analysts, the digital optimization process, web metrics, and key performance indicators, as well as the essentials of collaboration and generating support and buy-in while gaining your executive’s attention.
This is a planned future course and not on current schedules.
This course is intended to review theoretical, conceptual, and analytic issues associated with network perspectives on communicating and organizing. The course will review scholarship on the science of networks in communication across a wide array of disciplines in order to take an in-depth look at theories, methods, and tools to examine the structure and dynamics of networks.
An intermediate data wrangling and analysis class designed to provide students with an in-depth overview of collecting and analyzing Twitter data. Computational topics include composing, sending, and receiving Hypertext Transfer Protocol (HTTP) messages. Data wrangling topics include parsing json files, navigating recursively nested structures, and processing textual data. Analysis methods include machine learning, network analysis, topic modeling, time series, etc.
High-Performance Computing
This course provides an overview of state-of-the-art topics in Big Data Security, looking at data collection (smartphones, sensors, the Web), data storage and processing (scalable relational databases, Hadoop, Spark, etc.), extracting structured data from unstructured data, systems issues (exploiting multicore, security). Securing sensitive data, personal data and behavioral data while ensuring a respect for privacy will be a focus point in the course.
Introduces the main concepts and techniques of data mining (DM) and information retrieval (IR) systems. The content covers various data mining topics and methods to extract hidden and predictive patterns from large data collections. Theory and techniques for supervised, semi-supervised, and unsupervised, indexing, and retrieving relational, non-relational, text-based, vector, and multimedia databases are considered. Topics include an introduction to the ensemble leaning and feature importance, data mining process, mining frequent patterns, and pattern analysis, as well as different information retrieval models and evaluation, query languages and operations, indexing/searching methods, and recommender systems. Discussions and application to different domain contexts provide use case scenarios; emerging trends in the consideration of artificial intelligence and language models are also considered.
This course introduces students to the use of cloud computing for Artificial Intelligence/Machine Learning (AI/ML) and big data analytics. Topics include a survey of cloud computing platforms, architectures, and use-cases, including concepts such as cloud compute, cloud storage, cloud containers and applications, as well as serverless data flow designs for AI/ML and advanced analytics. Students will examine data science scaling techniques and algorithms using a variety of cluster and cloud paradigms, built atop cloud computing concepts in multiple commercial cloud platforms.
This course will provide in-depth treatment of the evolution of high performance, parallel computing architectures and how these architectures and computational ecosystems support data science. We will cover topics such as: parallel algorithms for numerical processing, parallel data search, and other parallel computing algorithms which facilitate advanced analytics. To reinforce lecture topics, learning activities will be completed using parallel computing techniques for modern multicore and multi-node systems. Parallel algorithms will be investigated, selected, and then developed for various scientific data analytics problems. Programming projects will be completed using Python and R, leveraging various parallel and distributed computing infrastructure such as AWS Elastic Map Reduce and Google Big Query. Students will research emerging parallel and scalable architectures for data analytics.
Sample Course Path
Students move through 8-week modules completing core courses and then progressing through emphasis area courses directly applicable to their area of study.